Optimal Transport and Brain Imaging
Fuctional connectomes, derived from functional magnetic resonance imaging (fMRI) is widely used to study functional organization of human brain. Individuals spend limited amount of time under scanner while resting (i.e., resting scan connectomes) or performing specific tasks (i.e., task-based connectomes). Removing head motions, skull stripping, registering to a common space, deriving time series out of a given atlas are typical things a researcher needs to do before any further analysis. Yet, traditionally different institutes and schools develop their own atlas or keep using a well-known set of brain mappings for their studies. Constructing conectomes that are derived differently in terms of geometry leads to a inconsistent pool of data that makes downstream analysis impossible unless we run all the preprocessing steps together using a same atlas. In MICCAI 2021 I, Amin Karbasi, and Dustin Scheinost proposed a new data-deriven algorithm based on optimal transport to generate time series data of individuals without having further preprocessing steps involved.

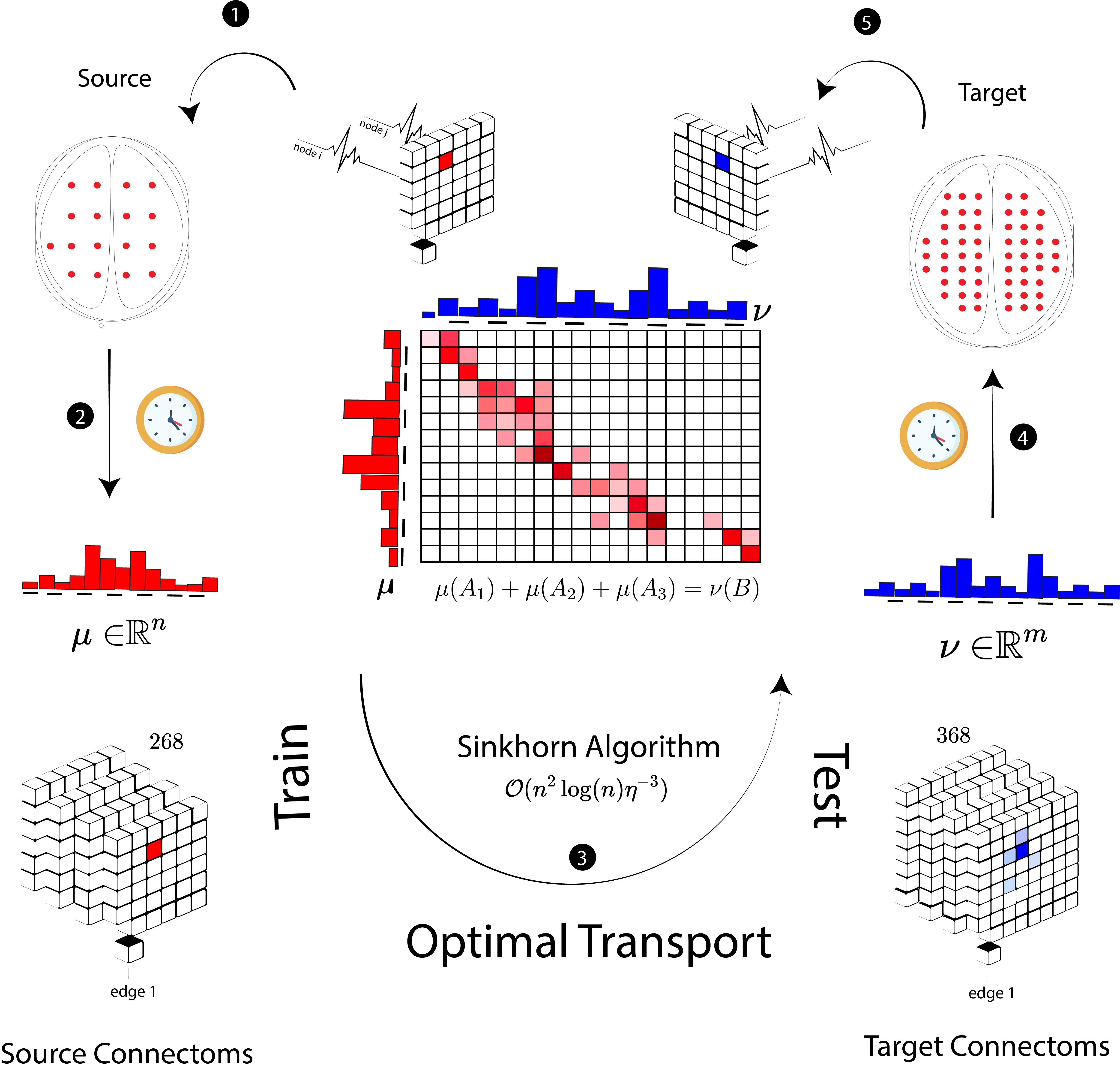
The main idea is pretty simple; optimal transport is defined over probability distributions with different supports and possibily located on different geometry. Suppose there are $m$ sources $x_1, \ldots, x_m $ for a commodity, with $a(x_i)$ units of supply at $x_i$ and $n$ sinks $y_1, \ldots, y_n$ for the commodity, with the demand $b(y_j)$ at $y_j$. If $a(x_i,\ y_j)$ is the unit cost of shipment from $x_i$ to $y_j$, find a flow that satisfies demand from supplies and minimizes the flow cost.
Similarly, we define a transportation problem between $\mu$ which are activity level of $n$ regions in brain based on a source atlas, and $\nu$ with $m$ values for target. Once we have an optimum mapping between $\mu$ and $\nu$ based on a given cost matrix $M$, transportaion comes for free. Therefore, we use some training data between these two atlases to find out the mapping and then use it as a universal plan to obtain $\nu$ for the individuals that we don’t have relative values in target. This process repeatedly happens in different time frames to construct final time series data. Using this algorithm, people don’t need to run all the preprocessing steps to obtain time series data in target. This method particularly shines when raw data are not available for various reasons including privacy or storage limits.